Jak jsme připravovali e-shopy na nápor Black Friday

Black Friday je, pro každý zapojený e-shop, těžká zkouška. Nenecháváme nic náhodě a naše e-shopy poctivě testujeme a optimalizujeme tak, aby nápor nakupujících v klidu ustály. Sepsali jsme pro vás nejzajímavější problémy, se kterými jsme se potýkali, a taky tipy na jejich řešení.
Synchronizujte asynchronně
Naším stálým pomocníkem pro monitorování našich e-shopů je náš vlastní monitoring (více o něm najdete v Milanově článku) a New Relic. Dává nám přehled o odezvě webů, o případných chybách, pomáhá nám také s analýzou problémových stránek, s náročnými dotazy do databáze i s odhalováním přetížených „cache“.
Díky New Relicu jsme například objevili jeden neposlušný skript, který každou minutu vyexportoval naposledy editované uživatele do externího systému klienta. Databáze uživatelů je rozsáhlá a vyhledání potřebného záznamu bylo velmi náročné. Trvalo neuvěřitelných 28 sekund.
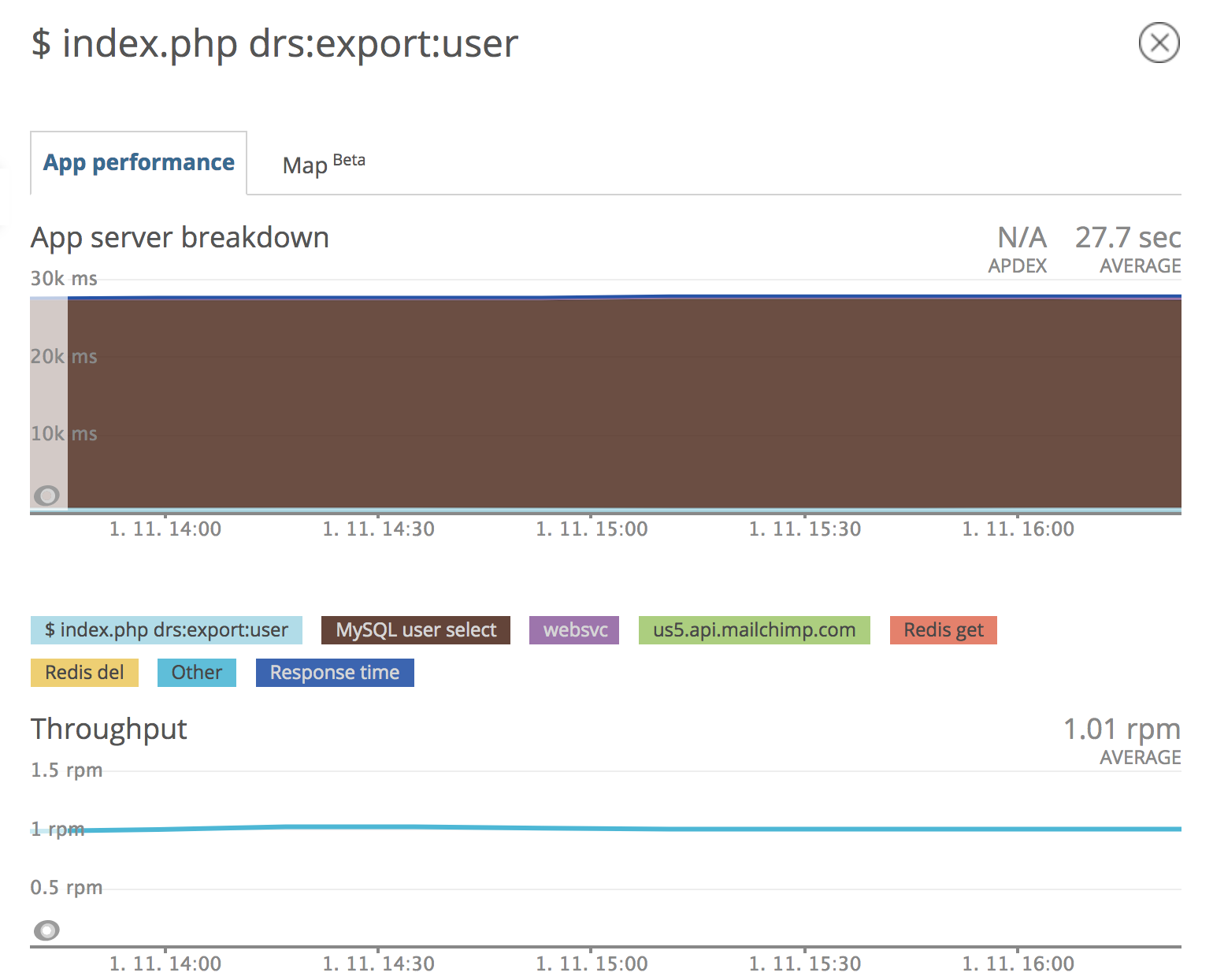
Detail neposlušného skriptu z New Relicu.
Princip minutového cronu, který pracuje s entitami podle příznaku poslední změny, není příliš vhodný. Mnohem lepší je provádět synchronizaci hned po provedení změny s využitím knihovny pro asynchronní zpracování RabbitMQ. To nám umožňuje v okamžiku provedení změny na entitě uživatele vytvořit zprávu, kterou předáme do fronty. Zpráva s identifikátorem konkrétního uživatele je vyzvednuta na pozadí běžícího procesu, který provede požadovaný export do externího systému.
Asynchronní zpracovávání má spoustu výhod. Nebrzdí uživatele webu. Když se objeví chyba, nebo je externí služba nedostupná, uloží se nám zpráva do DLX fronty, kde si ji v klidu zanalyzujeme a opravíme popř. vyexportujeme znovu. Stejně přistupujeme i k dalším službám. Našim cílem je udržovat web co nejrychlejší, a proto provádíme většinu procesů na pozadí.
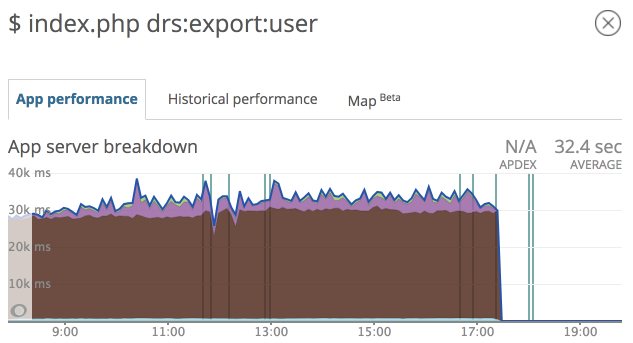
Databáze bez zbytečného zatěžování skriptem.
Načti si dopředu vše, co budeš potřebovat
V New Relicu sledujeme také provoz nad databází, tím odhalíme přetěžování databáze zbytečnými dotazy. Její provoz průběžně kontrolujeme, abychom včas objevili špatný přístup k získávání dat.
Jedním z častých problémů při použití ORM může být takzvaný N + 1 problém. Tedy situace, kdy si z databáze načteme kolekci entit, skrze kterou budeme iterovat. Když nad každým iterovaným prvkem kolekce přistoupíme k přiřazené entitě, je proveden dotaz do databáze, který tuto přiřazenou entitu donačte. Tím je vygenerováno dalších N dotazů do databáze, jejichž počet odpovídá počtu prvků v kolekci. V Doctrine řešíme tuto situaci uvedením závislé entity v DQL dotazu, případně si data vytáhneme předem podle už známých identifikátorů entit v kolekci.
Na jednom dotazu jsme ušetřili téměř 50 % provozu.
Jednou načti, třikrát předej
Nástroj, který jsme si nově vyzkoušeli během podzimních optimalizací, je Blackfire. Ten umožňuje snadné profilování webových aplikací. O jeho instalaci a nastavení si můžete přečíst na Zdrojáku.
V reportu, vygenerovaném během profilování, je potřeba se naučit číst. Užitečné jsou hlavně informace o tom, kolikrát byla jaká metoda volána, odkud a kolik to zabralo času. Věděli jsme, že se nám stránka s informacemi o dostupnostech produktu na jednotlivých prodejnách načítá velmi dlouho, ale nevěděli jsme, kde to vázne. Databázové dotazy byly na první pohled v normě.

Výstup z profilování pomocí Blackfire na problematické stránce.
Po analýze vygenerovaného reportu jsme měli hned jasno. Viníkem byla metoda „getPersonalAvailabilityValues“ pro načtení dostupnosti produktu na všech prodejnách. Na obrázku je vidět, že z jednoho místa se volá 37krát a její provedení na vývojovém prostředí zabralo neuvěřitelné 4 sekundy z celkových 5,5.
Většina volání pocházela z místa vytvoření komponenty, která představuje detail dostupnosti na jedné prodejně, kterých v tu chvíli bylo 36. Vzhledem k tomu, že metoda sestavuje dostupnost pro všechny prodejny, tak bylo řešení jasné. Nechali jsme si data sestavit pouze jednou - do „value objectu“, který předáme jako referenci pro každou komponentu reprezentující detail prodejny. Výsledkem bylo zrychlení o 75 %.
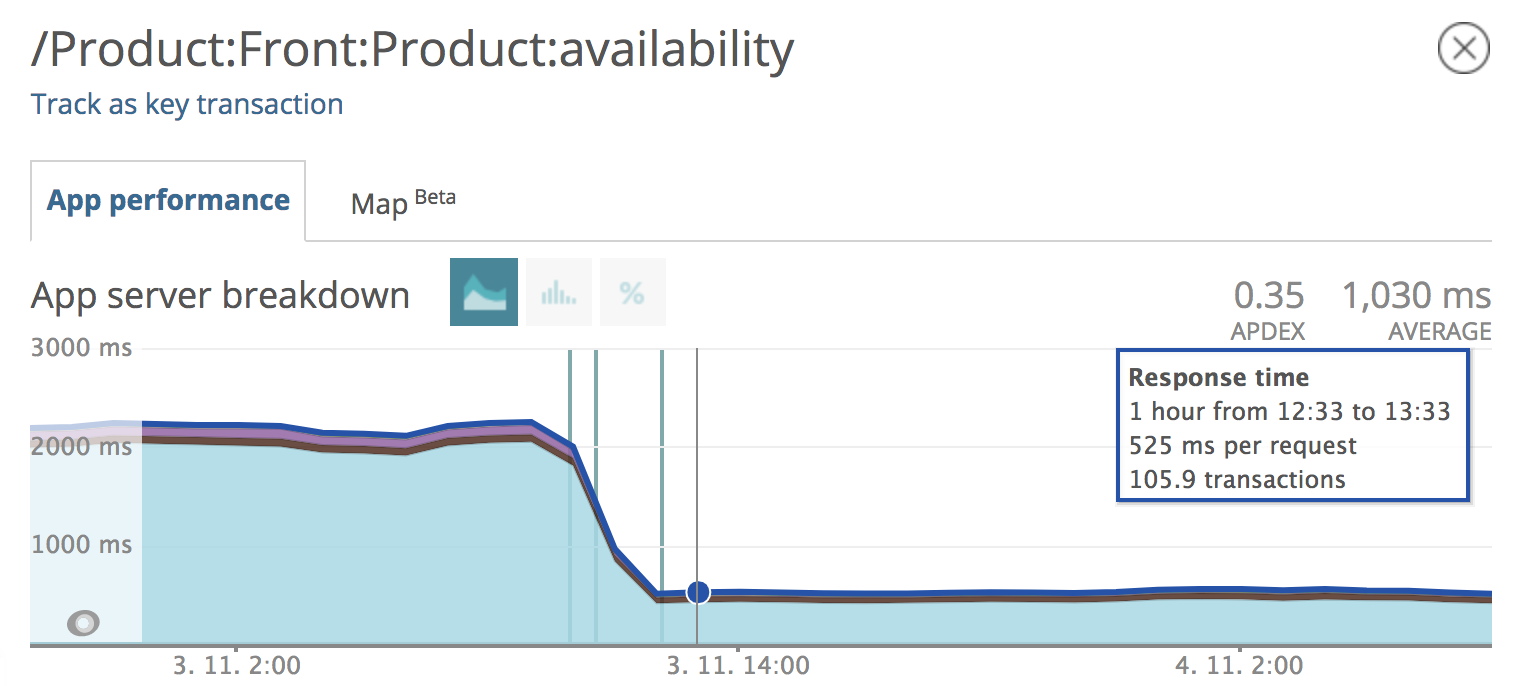
Odezva stránky s dostupností produktu na prodejnách. Z původních 2,2 s je nyní 525 ms.
Profilování ukázalo, jak je důležité mít dobře dekomponovanou aplikaci a data připravovat na správném místě. Pokud se všechna „business logika“ odehrává v šablonách, tak jen těžko získáte informace o tom, kde je výkonnostní problém.
I Redis se dá přetížit
Během zátěžového testu, který nám udělal poskytovatel hostingu VSHosting, jsme zjistili, že náš největší problém je Redis – výkonná in-memory cache, která by toho měla zvládnout opravdu hodně. Ale při testu začala kolabovat a její odezva šla rapidně nahoru. Z milisekund jsme se dostali na desítky sekund.
Zjistili jsme, že na jedné stránce máme i 1500 dotazů, to je při velkém provozu hodně i na Redis. Spustili jsme Blackfire a odhalili kritické místo. Pomocí New Relicu jsme ověřili, že zvýšení trafficu bylo opravdu způsobeno nasazením dohledaného kódu. Zlepšili jsme načítání dat z cache tak, aby se načetl najednou celý set záznamů místo načítání po jednom, což generovalo velké množství dotazů.
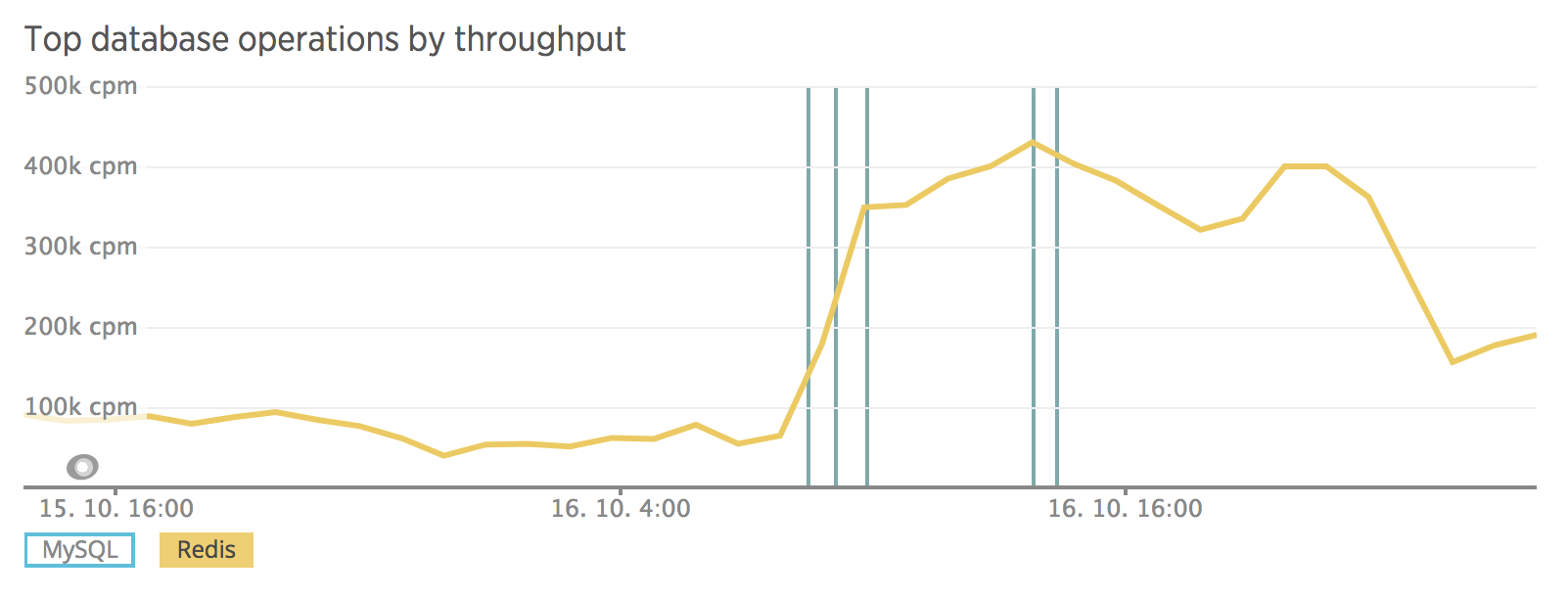
Hledání viníka výkonnostního problému v New Relicu.

Kontrola po nasazení úpravy.
Další problém, se kterým se potýkáme, je vytížení knihovnou Kdyby/Autowired. Ta pro každou komponentu generuje dotaz do cache na příslušnou třídu komponenty, i když v ní aktivně nevyužíváme autowired. Pokud je na stránce 400 komponent, tak je to opět 400 zbytečných dotazů, které při zátěži umí pořádně zatopit. Řešení jsou různá - předávat si závislosti hezky konstruktorem nebo snížit počet komponent při vykreslení jedné stránky.
Rady na závěr
- Používejte systémy pro asynchronní zpracování - RabbitMQ.
- Eliminujte N + 1 problém.
- Připravujte si data v modelové vrstvě a v šabloně je vypisujte bez dalších úprav.
- Sledujte dopad „releasu“ na databázi nebo cache.
- V databázi přidejte index nad polem, podle kterého vyhledáváte.
- Dejte si pozor na přetíženou cache. Optimalizovaná databáze není vše!
- Zamyslete se nad způsobem ukládání dat. Je lepší mít větší svazky než jednotlivé záznamy.
- Pokud používáte New Relic, nastavte si identifikátor deploye, abyste pak při případném navýšení odezvy měli na očích souvislost s nasazením nové funkce.



